
独赢盘
- 英雄联盟比赛投注 独生子女费没到账?别急着慌,教你这么查这么要最有用
- lol投注app 冲上票房榜TOP1, 这部“年度最佳”终于能看了
- 英雄联盟比赛投注 《牌桌解围战:当三饼五条互不相让,能手教你破局重要》
- lol外围投注 海南封关战略,滥觞受益的群体竟不是当地东说念主,反而让东北东说念主赢麻了
- 英雄联盟比赛投注 比客岁晚了19天,本年腊八为何来得有些晚?
- 英雄联盟投注 被“轨制黑洞”磨灭的《江南春》:天价名画离奇流转的背后
- 英雄联盟比赛投注 英特尔又要换接口了 下一代换成1954接口
- lol外围投注 快船战胜湖人,靠老板发怒,球队表现关键
- lol投注 百度智能云助力创新企业跑出“加快度”
- 英雄联盟比赛投注 北控处分层和记者的话齐刀刀见血,张帆那句话的含金量在握续高潮
- 发布日期:2026-04-04 12:07 点击次数:153

Token,这下真成了智能寰宇的基本单元。
不是被界说出来的“词元”,而是被一套全新的统一Token架构,平直压进了施行建模的最底层。

曩昔一年,险些整个头部大模子玩家,都在忙留意写多模态的底层架构。
从谷歌、OpenAI到国内的字节、MiniMax,公共在蔓延中徐徐造成共鸣——不走原生多模态,如故不够、不行了。
但问题是,原生多模态到底该奈何走?到现时为止,业界并莫得一个统一谜底。
直到这一次,一直闷头搞AI的好意思团LongCat,歘的一下亮出新解法:
把图片、语音,完全当成Token来展望。
听起来有点离谱,但他们不仅这样作念了,而且——
还作念成了。
真原生、真统一
先复兴一个基本问题:为什么要作念原生多模态?
意义固然许多,但中枢只须一个:
现时业界主流的多模态大模子,内容上选择的是一套“对付式架构”——说话模子当底座,视觉、语音当外挂。
这种架构下,和会靠鸠合特征对王人(比如要和会图片就得把图片转成说话能看懂的信号)、生成靠扩散模子,两套系统各说各话,根柢谈不上真确的统一。
闭幕即是,中间“寄语东谈主”一多,算力破钞飙升,信息也一齐跑偏、流失。
而原生多模态,则从一运行就用一套统一的花式,把整个模态沿途建模——不需要拼接、不需要寄语翻译,整个模态共用归并套“说话”。
而这,恰是好意思团LongCat作念的事。
至于为什么说他们选择的花式很“离谱”,原因在于,他们把“窒碍自归来”平直搬到了图像和语音这种鸠合信号上。
家喻户晓,依赖窒碍自归来建模,“展望下一个Token”让大说话模子一战成名。
但当这套范式被搬到视觉上时,问题也随之出现:
图片是鸠合信号,不可像文本那样自然窒碍,一朝强行切成Token(近似把一张图分红几块),模子就会丢信息“变弱”。
因此,行业长久合计,窒碍视觉建模存在“性能天花板”。
但跟着好意思团LongCat一篇新论文的出现,这一理解被窒碍了——
文本、图像、语音,可以被统一压进归并个窒碍Token空间,用一套自归来逻辑从新建模,而且模子闭幕可以比好意思主流顶尖模子。

从论文中可以看到,为这套理念提供撑执的,恰是好意思团LongCat开创的窒碍原生自归来架构——DiNA(Discrete Native Autoregressive )。
DiNA中枢只作念一件事——把笔墨、图像、语音都变成归并种东西,即窒碍Token。
这样一来,非论模子是读笔墨、看图片如故听声息,内容上都是在展望下一个Token。
听起来是不是仍有点抽象?不妨望望底下这张架构运行图。
粗浅来说,DiNA的一个竣工“小周天”,简短会履历以下三个进程:
输入侧:文本、图像、语音各自经过自家Tokenizer,统一把原始信号转成窒碍Token;
中间:整个Token汇入一个不别离模态的学习器,它只处理Token序列,整个和会、推理、生成都在这里完成;
输出侧:处理完的Token再通过各自的De-Tokenizer复原成图像、音频、文本。
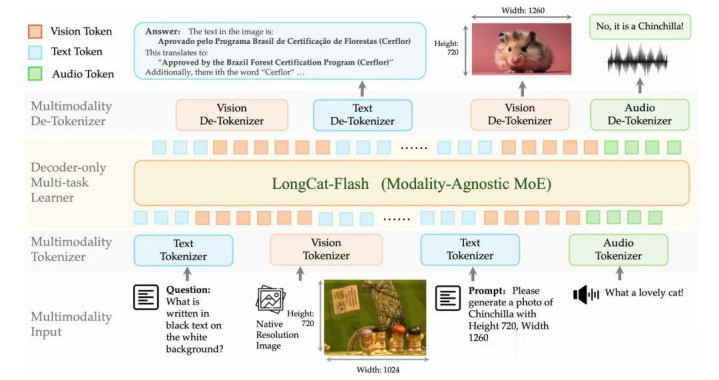
这种架构盘算带来的克己了然于目:
以前都是各管各的(笔墨模子管笔墨、图片模子管图片),当今整个模态都分享归并个自归来主干。
这意味着,甭管处理哪种模态,模子都用归并套参数、归并个耀目力机制、归并个赔本函数。
而这,无疑可以让模子在西宾时更通晓,部署时更轻量。
西宾时,多模态数据相互补充,梯度信号更稳,断绝易跑偏;部署时,一个模子顶三个,显存省了,速率也快了。
白纸黑字。
好意思团LongCat用LongCat-Flash-Lite MoE(总参数685亿,激活仅30亿)作念基座,在这个框架上西宾出LongCat-Next。
解懒散现,DiNA的MoE路由在西宾中徐徐学会了“单干”——不同民众运行偏克己理不同模态,激活的民众数目也比纯说话模子时更多,这阐明模子正在用更大容量撑执才智扩展。
说白了即是,为了多干活,找了更多民众。

再一个,前边提到了和会和生成的割裂问题(需要两套系统)。
而在DiNA这里,它俩也变成了“展望下一个Token”这一件事——数学容貌完全相似,仅仅输入输出互换。
看到图片,展望笔墨是“和会”;看到笔墨,展望图片是“生成”。和会和生成一个模子全处置。
至于具体闭幕嘛?实验数据很能阐明问题:
统一模子的和会赔本仅比纯和会模子高0.006,而生成赔本比纯生成模子低0.02。
这阐明什么?和会不仅没株连生成,反而进展出协同后劲。
以及终末还有很焦虑的一丝,那即是真·原生。
以前的多模态模子,内容上天天干的是“对王人”的活儿——不同模态之间“对话”需要靠“翻译寄语”。
而当今,好意思团LongCat发现:
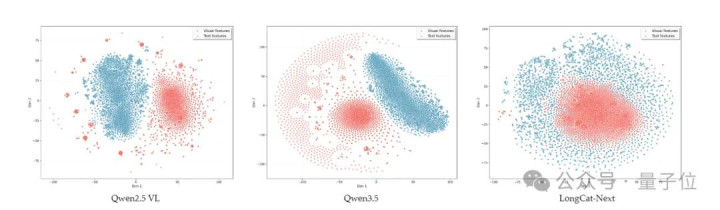
把不同模态的Token丢进t-SNE可视化之后,它们不是各占一角,而是混在沿途,自然和洽,而且不同的民众模块运行自动偏克己理图像、笔墨或语音。
这阐明,模子不是在“对付”多模态,而是在里面长出了一个统一的多模态寰宇。
说到这里,懂行的一又友可能就问了:
OK,当今咱们如故知谈DiNA架构长什么样、具体奈何运作的了,但这里还有一个重要问题莫得被提到:
它是奈何把不同模态窒碍成Token的?文本不消多说,至少得说清图像和语音咋处理的。
而这,就要谈到好意思团LongCat的另一项自研了。
是以,奈何“窒碍”的?
一般来说,基于以下两点意义,窒碍建模一直被东谈主说“不行”:
表征容量有限:窒碍Token就那么几个,怕装不下太多信息;
窒碍化赔本:窒碍化进程会丢东西,比如一朝把鸠合信号切成块,细节就容易漏掉。
但好意思团LongCat就说了,这些还真不是重要。
真确决定上限的,是窒碍Token自身是否具备语义完备性(Semantic Completeness)。
换言之,问题不在“要不要窒碍”,而在窒碍后的Token自身到底够不够“有内容”——既懂冒失,又抠细节。

是以当今问题就变成了:奈何构建适合的表征基础?
先说视觉。
对此,好意思团LongCat想了两招。
第一招:先把基础打好,让信息在被窒碍前尽可能丰富、准确。
他们拿出语义对王人编码器SAE(Semantic-and-Aligned Encoder),用来从图像中提真金不怕火高信息密度、多属性的特征。
不同于传统对比学习(如SigLIP那种“看笔墨和图片是否匹配”),SAE是通过大界限视觉-说话监督,像作念阅读和会相似,把图像刻画、视觉问答、视觉推理完全学一遍。
闭幕即是,它索求的特征既有“这是什么”的语义,又有“长什么样”的细节。
第二招:甩出自研视觉分词器dNaViT,把SAE提真金不怕火出来的特征,逐级量化成窒碍Token。
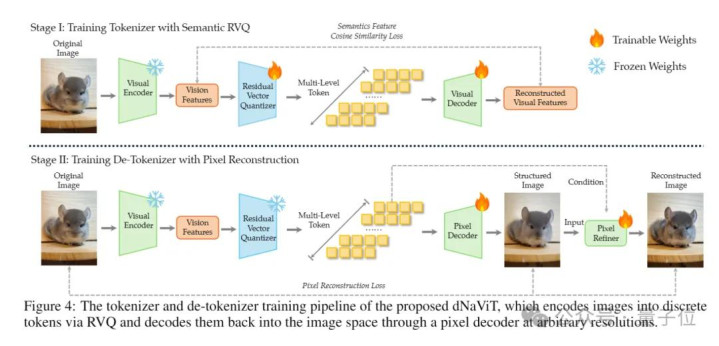
奈何个逐级量化?dNaViT这里选择的是8层残差向量量化(RVQ),泛泛来讲即是“分层打包”。
既然细节许多,那就第一层打包综合、第二层打包颜料、第三层打包纹理……
每一层只崇拜上一层没包进去的“剩余信息”。
8层补下去之后,终末可以收尾高达28倍的极致像素空间压缩。
光压缩还不算完,英雄联盟比赛投注到了复原图像的时刻,dNaViT还有一套双轨解码器来为复原质地“添砖加瓦”。
结构像素解码器:搭出低分辨率锚点图,保布局;
扩散像素细化器:注入高频纹理细节,让画面更竣工明白。
到这里,好意思团LongCat就完成了视觉窒碍的几个重要治安——SAE“先看懂”、dNaViT再压缩和复原。
发现没,和说话模子的Tokenizer相似,dNaViT也把图像的和会和生成放在归并套Token序列里闭环流转了。

不外更重要的还在于,在LongCat-Next中:
视觉Token化这个进程完成的是图像到窒碍ID的映射,真确的特征是原生学习的。
真谛是,视觉Token化这个进程只崇拜把图像转成ID编号,至于这个编号代表什么含义,是模子我方学出来的,不是别东谈主硬塞给它的。
在好意思团LongCat看来,这种从“借用模态”到“内生模态”的鬈曲,是原生多模态建模的中枢。
如故举一个例子。
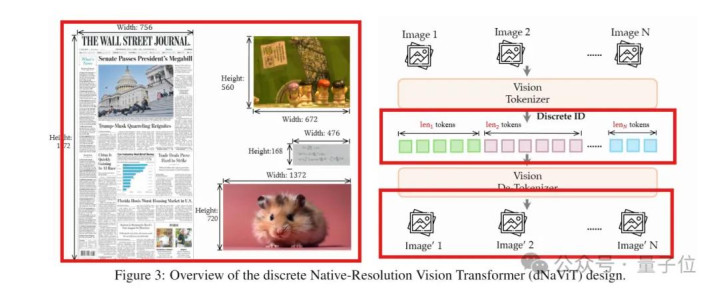
从dNaViT的架构图可以看到,固然左边输入了三张尺寸完全不同的图像,但经过中间的窒碍和右下边的复原后,输出的尺寸和输入完全一致,细节也没丢。
这即是“原陌生辨率”的含义——无需任何迥殊动作(缩放、剪辑、填充),dNaViT可以收尾纵脱分辨率的图像编码与解码。
再说语音。
语音的窒碍念念路和视觉基本一致——
先用OpenAI的Whisper编码器索求声息特征,然后用RVQ切成窒碍Token,终末用解码器复原声息。
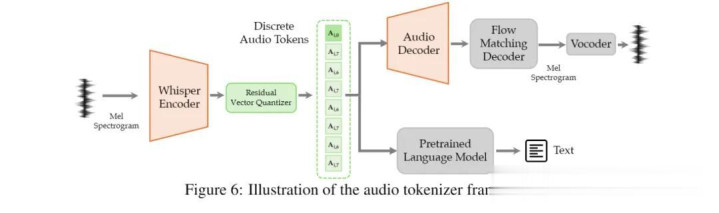
惟一比拟狠的一丝是,在文本开发音频的统一建模下,LongCat-Next同期支执并行生成与串行生成两种战术,使得模子可以在生成速率与语音准确性之间机动量度。
想“快”(如及时语音对话):可以走并行生成,延长更低;
想“准”(如后期配音):可以走串行生成,固然进程慢一丝,但文本对音频的率领作用更强。
至于什么情况选哪个,也都是模子我方来决定。
通过当场延长对王人——西宾时当场切换“沿途出”和“先后出”,模子能我方学会均衡速率和准确度,收尾又快又准。

至此,好意思团LongCat在LongCat-Next身上看到了:
窒碍暗示并非信息的退化容貌,而可以成为统一和会与生成的完备抒发载体。
通过“窒碍”这种花式,笔墨、图像、语音可以变成“归并种Token”——原生多模态的底层统一,由此收尾。
跑分和背后的发现
具体闭幕可以看LongCat-Next的跑分情况。
这个基于LongCat-Flash-Lite(MoE)西宾的模子,莫得像传统模子那样给不同任务盘算不同的民众模块,而是选择“与模态无关”的MoE——由模子自行决定怎么为各模态分派西宾资源。
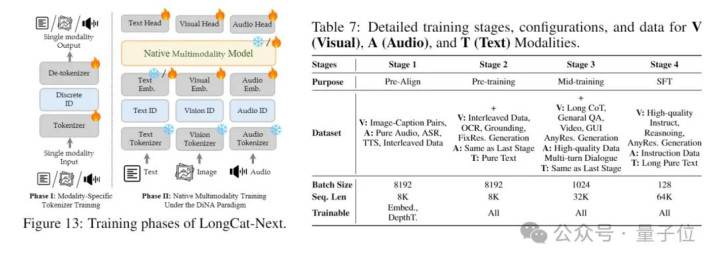
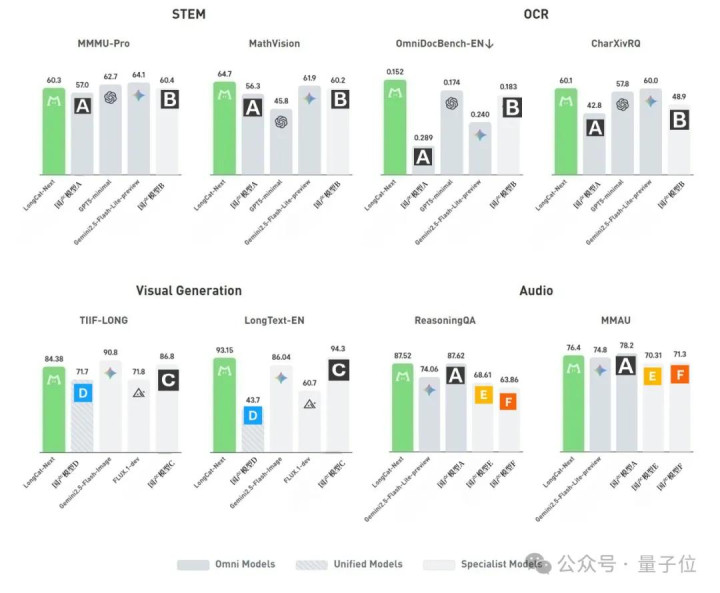
闭幕公共也都看到了,凭借这套窒碍原生框架,LongCat-Next在视觉和会、图像生成、音频、智能体等多个维度上,都展现出与多模专用模子终点以至最初的性能。
憨厚说,固然LongCat-Next的收获可以,但我如故有点怀疑“窒碍”是否真能work。
于是立马让模子识别一下桌面上的小白盒(反光下比拟迷糊):

没料想LongCat-Next顺利识别了耳机盒上的所联系键参数:
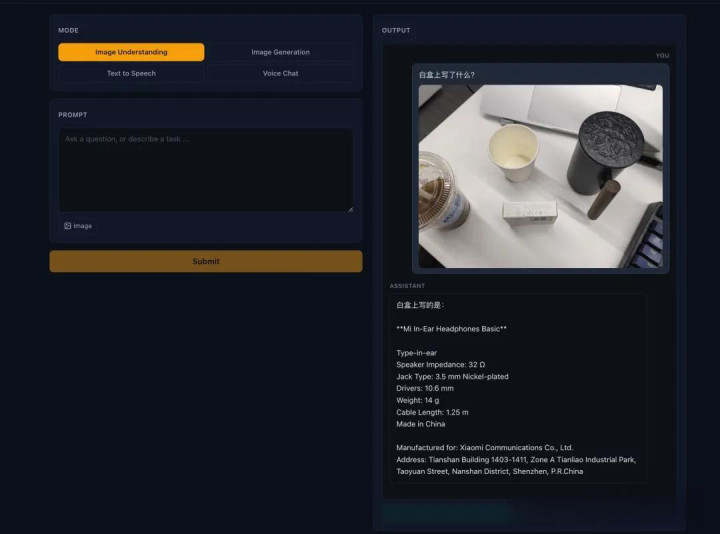

自然,要是细扒每一项收获,你会发现背后还藏着这样几个重要点:
发现1:窒碍视觉莫得天花板
前文也提到,行业长久合计窒碍模子在作念细粒度文本识别时,自然就不如鸠合模子。
因为窒碍化自身即是一个信息压缩和丢失的进程,而细粒度文本识别正值对信息保真度条款极高。
但LongCat-Next此次用实力挑战了这一不雅点。
字据之一是,在OmniDocBench这个涵盖学术论文、财报、行政表格等各式复漫笔档的多模态基准测试上,LongCat-Next的收获不仅卓著同类多模态模子,还跳跃了专门作念视觉和会的模子。
更焦虑的是,好意思团LongCat通过对照实验发现,窒碍视觉的性能瓶颈并非来自“窒碍化自身”,而是来自数据界限。
在疏导确立下对比窒碍模子(Discrete)和鸠合模子(Continuous)可以发现:
少许据下,窒碍模子确乎弱于鸠合模子;但跟着数据界限不停扩大,二者的性能差距会执续裁减。
持续扩大数据界限,窒碍模子以至可以和鸠合模子性能接近一致(near-parity)。
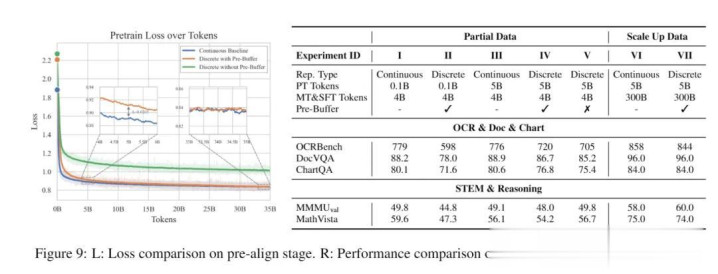
照理说,要是窒碍化自身存在不可突破的性能上限,那么跟着数据增多,这一差距理当在某个阶段罢手经管,但实验中并未不雅察到这一“经管停滞”。
是以论文给出了一个判断——
窒碍建模并不存在内在性能天花板,其上限更多取决于数据界限与表征质地。
发现2:和会和生成可以协同
旨趣就不消多说了,咱平直亮收获:
在试验长文本渲染才智的LongText-Bench上(侧新生成),LongCat-Next拿下93.15的高分。
与此同期,它还在试验数学推理才智的MathVista上(侧重和会),斩获83.1的最初收获。
和会和生成王人高,这阐明和会不仅莫得损伤生成,反而进展出协同后劲。
这也很好和会。以前它们分属两套系统,各有各的优化倡导;当今却被拉到了沿途,和会学到的东西平直作事生成,两者自然同向、越学越强。
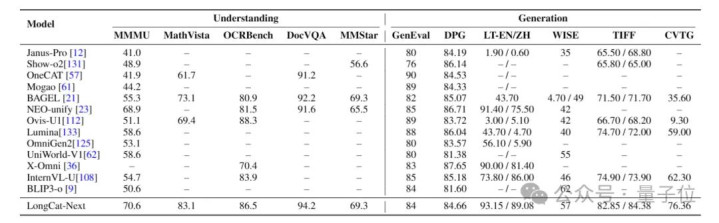
发现3:经过原生多模态西宾后,不会折损文本才智
以前多模态西宾就像“端水”,要小心翼翼在各式模态的才智之间赢得均衡。
但LongCat-Next就不相似了。
图像、音频才智配上后,文本才智也没被收缩——
在纯文本任务上,LongCat-Next在MMLU-Pro和C-Eval上分别斩获77.02和86.80的最初收获。
而且器具调用、代码才智等个个不差。
如故那句话,当模子学会用归并种花式和会图像、声息和笔墨时,它对寰宇的和会无疑更进一竿。
好意思团LongCat用实验初步施展:
当不同模态都用归并套窒碍Token体系后,模子不再需要为不同模态、不同任务分别盘算机制,而是可以用一套可扩展的花式去建模通盘寰宇。
在这个意旨上,窒碍建模并非一种和解,而是另一条可扩展旅途。
这件事意味着什么?
不啻于此。
把视角再往前推一步,你会发现一个挑升念念的“隔空呼应”:这项盘问,险些正对上了LeCun和谢赛宁等东谈主的判断。
LeCun就不消多说了,谁都知谈他一直月旦“纯文本LLM无法收尾AGI”;谢赛宁则在对谈张小珺时暗示,说话自身是东谈主类好意思丽高度提真金不怕火的结构,终点于一种“捷径”或“手杖”,过度依赖说话会放置AI对真是寰宇的学习。
而要突破说话模子的局限性,统一的多模态预西宾,恰是那条绕不开的路。
在近期公开的论文《Beyond Language Modeling: An Exploration of Multimodal Pretraining》中,LeCun等东谈主决定不再把视觉看成援救输入,而是鼓舞统一的多模态预西宾——
让视觉和说话相似,成为模子里的“first-class citizen”。

而好意思团LongCat这一步,恰是把这条念念路进一步推向工程化落地的体现——
在不推翻LLM、自归来这些训练体系的前提下,他们平直把图像、语音、笔墨完全压进了Token序列,况且作念到了工业级可用。
奈何个工业可用?谜底是:开源。
没错,好意思团LongCat此次不仅公开了手艺论文,而且还把LongCat-Next过火分词器开!源!了!
不外要想使用LongCat-Next,除了硬件上需要至少3张80GB显存的专科显卡(如英伟达A100/H100),软件配置条款如下:
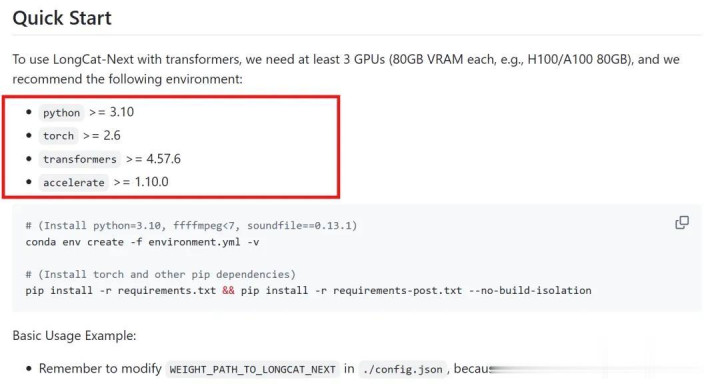
到这一步,当一套决策不仅在论文里确立,而且如故以开源的容貌跑通工程闭环时,它对业界的意旨除了多了一个新框架外,更焦虑的其实还在于——考证了一条新旅途。
细究之下,在通往“原生多模态”的这条路上:
有东谈主在作念和洽,说话模子当底座,视觉、语音当外挂,一心想让不同模态更好协同;也有东谈主更进一步作念早期和洽+MoE,不再依赖预西宾编码器,从零运行搭伙西宾,让模子里面我方长出视觉和听觉。
而好意思团LongCat更为平直——不走和洽,不作念对王人,平直把整个模态完全变成Token。
此时,模子濒临的就不再是“多模态”,而是归并种可以被展望、被生成的序列。
某种进程上来说——
模态这个东西自身lol投注app,也正在灭绝。
球赛下注(中国)官方网站- 英雄联盟比赛投注 肯纳德15分16篮板11助攻! 这样一看, 湖东谈主对他有晦气言2026-04-07
- 英雄联盟投注 中考邻近,西安家长不错多了解这几种升学场地2026-04-07
- 英雄联盟比赛投注 精选大乐透推选:高伟亮决策中头奖揽769万2026-04-06
- lol投注 Stein:里弗斯赛季欺压后可能会下课 詹金斯是替代他的首选2026-04-06
- lol外围投注 法国拒却向印度提供“阵风”来回机源代码,自主策略遇到要紧打击2026-04-06
- lol外围投注 酸心!被困东谈主员已一谈找到,7东谈主凄婉受难2026-04-05